@Max King
你不夠敬業啊,寫詩最重要的——意境——居然都給你忘了?!
當然了,作為碼農,怎麼寫「最美」我是不懂的,不過咱們有辦法。既然是寫楹聯,自然要仿古,而仿古的話最好的案例不是《全唐詩》麼?于是——我們可以統計《全唐詩》的語料,然后看哪個對聯對的和《全唐詩》最相似,不就結了?
首先把《全唐詩》語料整理成一行只有一句話的形式,我是用 sublime text 正則。
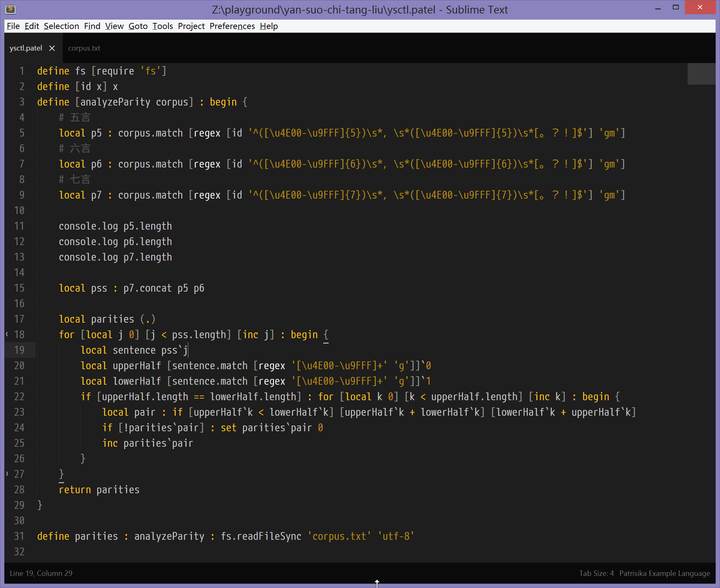
然后,統計《全唐詩》中的對仗。其實挺簡單的(語言是 patel,我待會發 gitcafe 的時候會轉[bian]換[yi]成 javascript):
// 為什麼是 gitcafe 呢?因為語料太大了,gh 上傳慢
————
@Max King
快發表格給我,懶得去翻廣韻了
———————————————————————————————————————————
@Max King
表格收到了,咱們繼續。
按照
@鳥飛
給出的提示,可以大幅度減少需要計算的下聯數目。五個字的選擇如下:
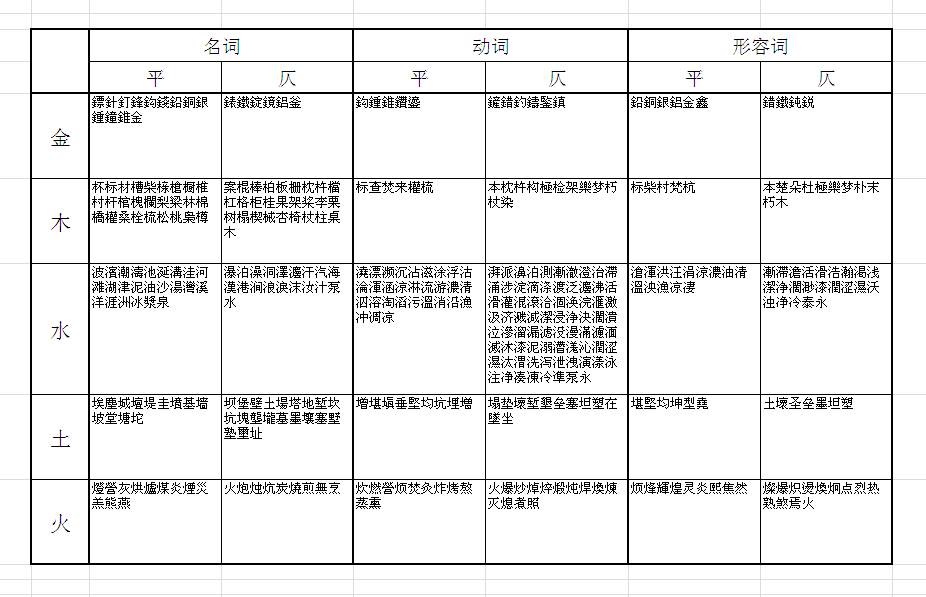
水部,兩可,名詞火部,平聲,動詞土部,兩可,名詞/形容詞木部,仄聲,名詞/形容詞金部,仄聲,名詞
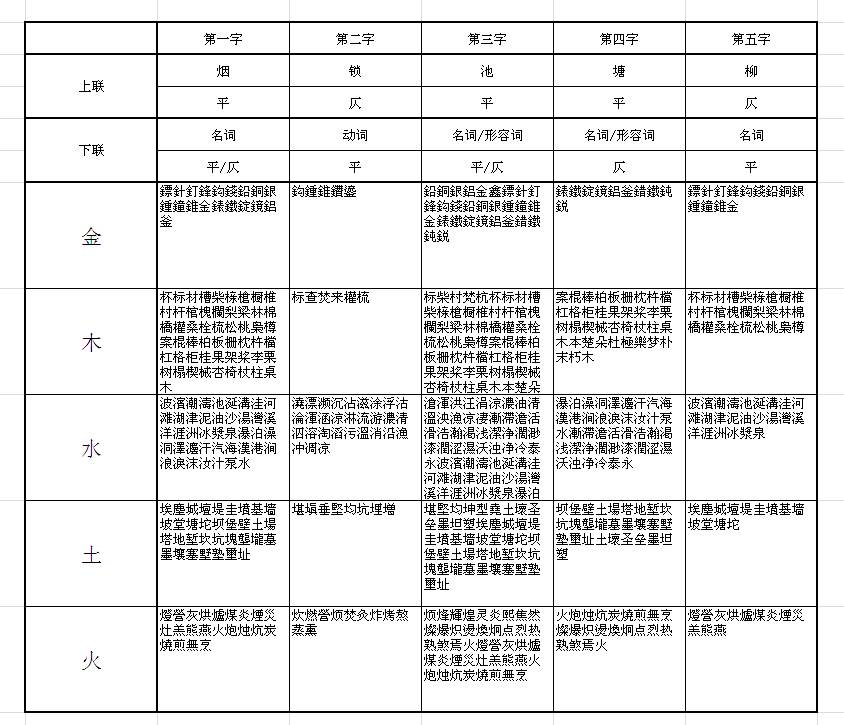
按照這個規律選字,構造句子,根據《全唐詩》中已有的對仗頻率計算分數,得到的結果是:
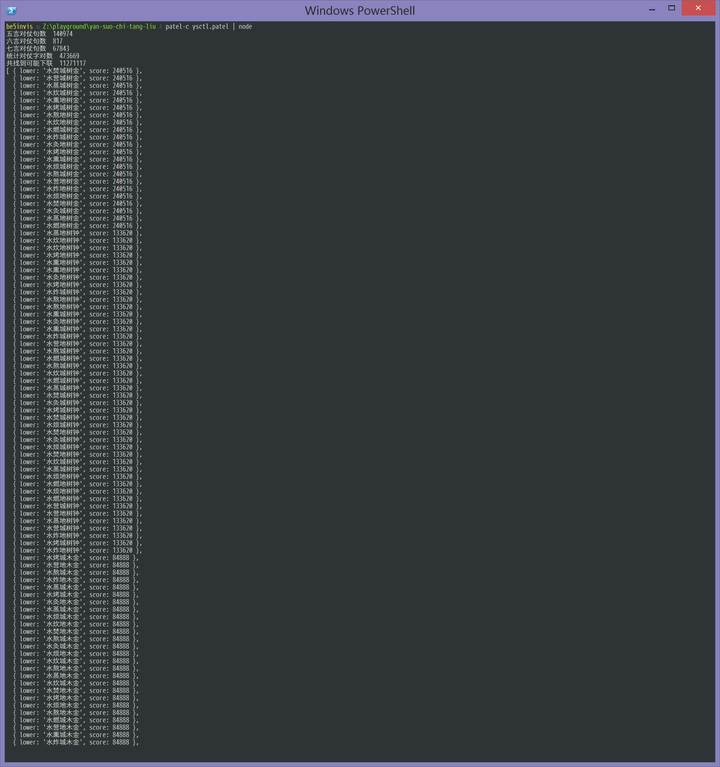
這個就是統計學意義上最「工整」的對聯了。但是「水焚城樹金」看上去還是古怪,因此還需要統計另一樣東西:Markov 特征,讓他們盡量組成句子。
(未完待續)
———————————————————————————————————————————
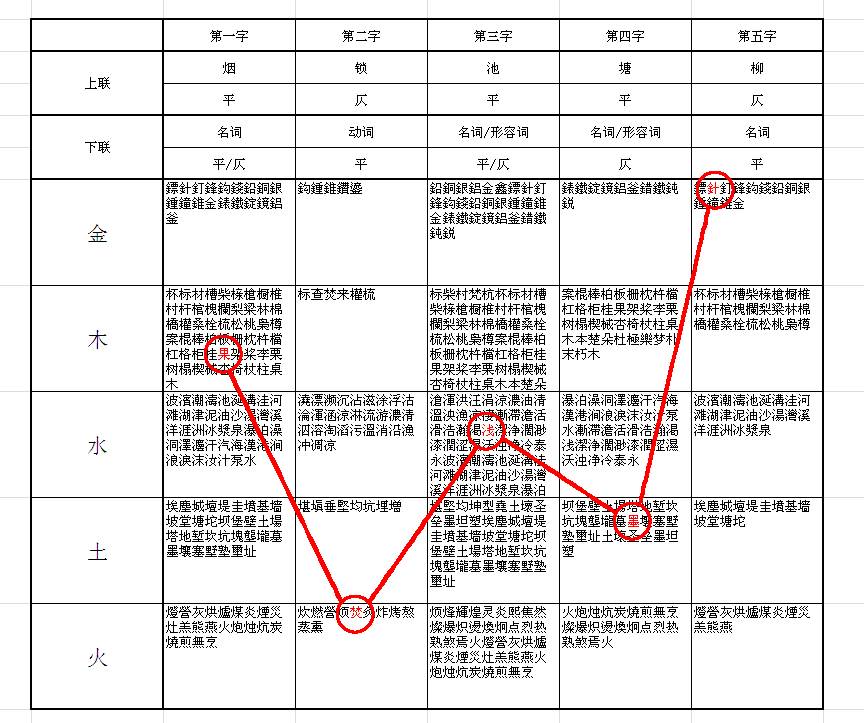
統計了 digraph,得到的結果是這樣的:
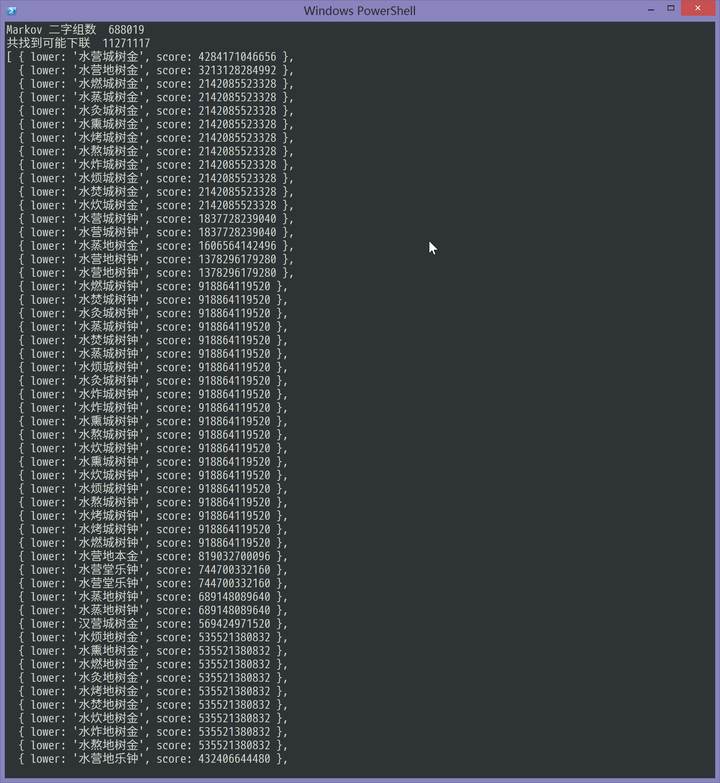
嗯,這回「水」不會「焚」東西了,果然有改進啊!請叫我詩人和文豪,謝謝。然而,這算法仍然需要繼續改進,所以仍然是未完待續。
ps. 如果只考慮 Markov 特征的話:

結尾統一到「堂樂鐘」了……